Memgraph
Memgraph is an open-source graph database, tuned for dynamic analytics environments and compatible with Neo4j. To query the database, Memgraph uses Cypher - the most widely adopted, fully-specified, and open query language for property graph databases.
This notebook will show you how to query Memgraph with natural language and how to construct a knowledge graph from your unstructured data.
But first, make sure to set everything up.
Setting up
To go over this guide, you will need Docker and Python 3.x installed.
To quickly run Memgraph Platform (Memgraph database + MAGE library + Memgraph Lab) for the first time, do the following:
On Linux/MacOS:
curl https://install.memgraph.com | sh
On Windows:
iwr https://windows.memgraph.com | iex
Both commands run a script that downloads a Docker Compose file to your system, builds and starts memgraph-mage and memgraph-lab Docker services in two separate containers. Now you have Memgraph up and running! Read more about the installation process on Memgraph documentation.
To use LangChain, install and import all the necessary packages. We'll use the package manager pip, along with the --user flag, to ensure proper permissions. If you've installed Python 3.4 or a later version, pip is included by default. You can install all the required packages using the following command:
pip install langchain langchain-openai neo4j --user
You can either run the provided code blocks in this notebook or use a separate Python file to experiment with Memgraph and LangChain.
Natural language querying
Memgraph's integration with LangChain includes natural language querying. To utilized it, first do all the necessary imports. We will discuss them as they appear in the code.
First, instantiate MemgraphGraph. This object holds the connection to the running Memgraph instance. Make sure to set up all the environment variables properly.
import os
from langchain_community.chains.graph_qa.memgraph import MemgraphQAChain
from langchain_community.graphs import MemgraphGraph
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
url = os.environ.get("MEMGRAPH_URI", "bolt://localhost:7687")
username = os.environ.get("MEMGRAPH_USERNAME", "")
password = os.environ.get("MEMGRAPH_PASSWORD", "")
graph = MemgraphGraph(
url=url, username=username, password=password, refresh_schema=False
)
The refresh_schema is initially set to False because there is still no data in the database and we want to avoid unnecessary database calls.
Populating the database
To populate the database, first make sure it's empty. The most efficient way to do that is to switch to the in-memory analytical storage mode, drop the graph and go back to the in-memory transactional mode. Learn more about Memgraph's storage modes.
The data we'll add to the database is about video games of different genres available on various platforms and related to publishers.
# Drop graph
graph.query("STORAGE MODE IN_MEMORY_ANALYTICAL")
graph.query("DROP GRAPH")
graph.query("STORAGE MODE IN_MEMORY_TRANSACTIONAL")
# Creating and executing the seeding query
query = """
MERGE (g:Game {name: "Baldur's Gate 3"})
WITH g, ["PlayStation 5", "Mac OS", "Windows", "Xbox Series X/S"] AS platforms,
["Adventure", "Role-Playing Game", "Strategy"] AS genres
FOREACH (platform IN platforms |
MERGE (p:Platform {name: platform})
MERGE (g)-[:AVAILABLE_ON]->(p)
)
FOREACH (genre IN genres |
MERGE (gn:Genre {name: genre})
MERGE (g)-[:HAS_GENRE]->(gn)
)
MERGE (p:Publisher {name: "Larian Studios"})
MERGE (g)-[:PUBLISHED_BY]->(p);
"""
graph.query(query)
[]
Notice how the graph object holds the query method. That method executes query in Memgraph and it is also used by the MemgraphQAChain to query the database.
Refresh graph schema
Since the new data is created in Memgraph, it is necessary to refresh the schema. The generated schema will be used by the MemgraphQAChain to instruct LLM to better generate Cypher queries.
graph.refresh_schema()
To familiarize yourself with the data and verify the updated graph schema, you can print it using the following statement:
print(graph.get_schema)
Node labels and properties (name and type) are:
- labels: (:Publisher)
properties:
- name: string
- labels: (:Game)
properties:
- name: string
- labels: (:Genre)
properties:
- name: string
- labels: (:Platform)
properties:
- name: string
Nodes are connected with the following relationships:
(:Game)-[:AVAILABLE_ON]->(:Platform)
(:Game)-[:HAS_GENRE]->(:Genre)
(:Game)-[:PUBLISHED_BY]->(:Publisher)
Querying the database
To interact with the OpenAI API, you must configure your API key as an environment variable. This ensures proper authorization for your requests. You can find more information on obtaining your API key here. To configure the API key, you can use Python os package:
os.environ["OPENAI_API_KEY"] = "your-key-here"
Run the above code snippet if you're running the code within the Jupyter notebook.
Next, create MemgraphQAChain, which will be utilized in the question-answering process based on your graph data. The temperature parameter is set to zero to ensure predictable and consistent answers. You can set verbose parameter to True to receive more detailed messages regarding query generation.
chain = MemgraphQAChain.from_llm(
ChatOpenAI(temperature=0),
graph=graph,
model_name="gpt-4-turbo",
allow_dangerous_requests=True
)
Now you can start asking questions!
response = chain.invoke("Which platforms is Baldur's Gate 3 available on?")
print(response["result"])
Baldur's Gate 3 is available on PlayStation 5, Mac OS, Windows, and Xbox Series X/S.
response = chain.invoke("Is Baldur's Gate 3 available on Windows?")
print(response["result"])
Yes, Baldur's Gate 3 is available on Windows.
Chain modifiers
To modify the behavior of your chain and obtain more context or additional information, you can modify the chain's parameters.
Return direct query results
The return_direct modifier specifies whether to return the direct results of the executed Cypher query or the processed natural language response.
# Return the result of querying the graph directly
chain = MemgraphQAChain.from_llm(
ChatOpenAI(temperature=0),
graph=graph,
return_direct=True,
allow_dangerous_requests=True,
model_name="gpt-4-turbo"
)
response = chain.invoke("Which studio published Baldur's Gate 3?")
print(response["result"])
[{'publisher.name': 'Larian Studios'}]
Return query intermediate steps
The return_intermediate_steps chain modifier enhances the returned response by including the intermediate steps of the query in addition to the initial query result.
# Return all the intermediate steps of query execution
chain = MemgraphQAChain.from_llm(
ChatOpenAI(temperature=0),
graph=graph,
allow_dangerous_requests=True,
return_intermediate_steps=True,
model_name="gpt-4-turbo"
)
response = chain.invoke("Is Baldur's Gate 3 an Adventure game?")
print(f"Intermediate steps: {response['intermediate_steps']}")
print(f"Final response: {response['result']}")
Intermediate steps: [{'query': 'MATCH (:Game {name: "Baldur\'s Gate 3"})-[:HAS_GENRE]->(:Genre {name: "Adventure"})\nRETURN "Yes"'}, {'context': [{'"Yes"': 'Yes'}]}]
Final response: Yes, Baldur's Gate 3 is an Adventure game.
Limit the number of query results
The top_k modifier can be used when you want to restrict the maximum number of query results.
# Limit the maximum number of results returned by query
chain = MemgraphQAChain.from_llm(
ChatOpenAI(temperature=0),
graph=graph,
top_k=2,
allow_dangerous_requests=True,
model_name="gpt-4-turbo"
)
response = chain.invoke("What genres are associated with Baldur's Gate 3?")
print(response["result"])
Adventure, Role-Playing Game
Advanced querying
As the complexity of your solution grows, you might encounter different use-cases that require careful handling. Ensuring your application's scalability is essential to maintain a smooth user flow without any hitches.
Let's instantiate our chain once again and attempt to ask some questions that users might potentially ask.
chain = MemgraphQAChain.from_llm(
ChatOpenAI(temperature=0),
graph=graph,
model_name="gpt-4-turbo",
allow_dangerous_requests=True
)
response = chain.invoke("Is Baldur's Gate 3 available on PS5?")
print(response["result"])
I don't know the answer.
The generated Cypher query looks fine, but we didn't receive any information in response. This illustrates a common challenge when working with LLMs - the misalignment between how users phrase queries and how data is stored. In this case, the difference between user perception and the actual data storage can cause mismatches. Prompt refinement, the process of honing the model's prompts to better grasp these distinctions, is an efficient solution that tackles this issue. Through prompt refinement, the model gains increased proficiency in generating precise and pertinent queries, leading to the successful retrieval of the desired data.
Prompt refinement
To address this, we can adjust the initial Cypher prompt of the QA chain. This involves adding guidance to the LLM on how users can refer to specific platforms, such as PS5 in our case. We achieve this using the LangChain PromptTemplate, creating a modified initial prompt. This modified prompt is then supplied as an argument to our refined MemgraphQAChain instance.
MEMGRAPH_GENERATION_TEMPLATE = """Your task is to directly translate natural language inquiry into precise and executable Cypher query for Memgraph database.
You will utilize a provided database schema to understand the structure, nodes and relationships within the Memgraph database.
Instructions:
- Use provided node and relationship labels and property names from the
schema which describes the database's structure. Upon receiving a user
question, synthesize the schema to craft a precise Cypher query that
directly corresponds to the user's intent.
- Generate valid executable Cypher queries on top of Memgraph database.
Any explanation, context, or additional information that is not a part
of the Cypher query syntax should be omitted entirely.
- Use Memgraph MAGE procedures instead of Neo4j APOC procedures.
- Do not include any explanations or apologies in your responses.
- Do not include any text except the generated Cypher statement.
- For queries that ask for information or functionalities outside the direct
generation of Cypher queries, use the Cypher query format to communicate
limitations or capabilities. For example: RETURN "I am designed to generate
Cypher queries based on the provided schema only."
Schema:
{schema}
With all the above information and instructions, generate Cypher query for the
user question.
If the user asks about PS5, Play Station 5 or PS 5, that is the platform called PlayStation 5.
The question is:
{question}"""
MEMGRAPH_GENERATION_PROMPT = PromptTemplate(
input_variables=["schema", "question"], template=MEMGRAPH_GENERATION_TEMPLATE
)
chain = MemgraphQAChain.from_llm(
ChatOpenAI(temperature=0),
cypher_prompt=MEMGRAPH_GENERATION_PROMPT,
graph=graph,
model_name="gpt-4-turbo",
allow_dangerous_requests=True
)
response = chain.invoke("Is Baldur's Gate 3 available on PS5?")
print(response["result"])
Yes, Baldur's Gate 3 is available on PS5.
Now, with the revised initial Cypher prompt that includes guidance on platform naming, we are obtaining accurate and relevant results that align more closely with user queries.
This approach allows for further improvement of your QA chain. You can effortlessly integrate extra prompt refinement data into your chain, thereby enhancing the overall user experience of your app.
Constructing knowledge graph
Transforming unstructured data to structured is not an easy or straightforward task. This guide will show how LLMs can be utilized to help us there and how to construct a knowledge graph in Memgraph. After knowledge graph is created, you can use it for your GraphRAG application.
The steps of constructing a knowledge graph from the text are:
- Extracting structured information from text: LLM is used to extract structured graph information from text in a form of nodes and relationships.
- Storing into Memgraph: Storing the extracted structured graph information into Memgraph.
Extracting structured information from text
Besides all the imports in the setup section, import LLMGraphTransformer and Document which will be used to extract structured information from text.
from langchain_experimental.graph_transformers import LLMGraphTransformer
from langchain_core.documents import Document
Below is an example text about Charles Darwin (source) from which knowledge graph will be constructed.
text = """
Charles Robert Darwin was an English naturalist, geologist, and biologist,
widely known for his contributions to evolutionary biology. His proposition that
all species of life have descended from a common ancestor is now generally
accepted and considered a fundamental scientific concept. In a joint
publication with Alfred Russel Wallace, he introduced his scientific theory that
this branching pattern of evolution resulted from a process he called natural
selection, in which the struggle for existence has a similar effect to the
artificial selection involved in selective breeding. Darwin has been
described as one of the most influential figures in human history and was
honoured by burial in Westminster Abbey.
"""
The next step is to initialize LLMGraphTransformer from the desired LLM and convert the document to the graph structure.
llm = ChatOpenAI(temperature=0, model_name="gpt-4-turbo")
llm_transformer = LLMGraphTransformer(llm=llm)
documents = [Document(page_content=text)]
graph_documents = llm_transformer.convert_to_graph_documents(documents)
Under the hood, LLM extracts important entities from the text and returns them as a list of nodes and relationships. Here's how it looks like:
print(graph_documents)
[GraphDocument(nodes=[Node(id='Charles Robert Darwin', type='Person', properties={}), Node(id='Alfred Russel Wallace', type='Person', properties={}), Node(id='Westminster Abbey', type='Location', properties={}), Node(id='Natural Selection', type='Concept', properties={}), Node(id='Evolutionary Biology', type='Field', properties={}), Node(id='Naturalist', type='Profession', properties={}), Node(id='Geologist', type='Profession', properties={}), Node(id='Biologist', type='Profession', properties={})], relationships=[Relationship(source=Node(id='Charles Robert Darwin', type='Person', properties={}), target=Node(id='Evolutionary Biology', type='Field', properties={}), type='CONTRIBUTED_TO', properties={}), Relationship(source=Node(id='Charles Robert Darwin', type='Person', properties={}), target=Node(id='Alfred Russel Wallace', type='Person', properties={}), type='COLLABORATED_WITH', properties={}), Relationship(source=Node(id='Charles Robert Darwin', type='Person', properties={}), target=Node(id='Natural Selection', type='Concept', properties={}), type='PROPOSED', properties={}), Relationship(source=Node(id='Charles Robert Darwin', type='Person', properties={}), target=Node(id='Westminster Abbey', type='Location', properties={}), type='BURIED_AT', properties={}), Relationship(source=Node(id='Charles Robert Darwin', type='Person', properties={}), target=Node(id='Naturalist', type='Profession', properties={}), type='WAS', properties={}), Relationship(source=Node(id='Charles Robert Darwin', type='Person', properties={}), target=Node(id='Geologist', type='Profession', properties={}), type='WAS', properties={}), Relationship(source=Node(id='Charles Robert Darwin', type='Person', properties={}), target=Node(id='Biologist', type='Profession', properties={}), type='WAS', properties={})], source=Document(metadata={}, page_content='\n Charles Robert Darwin was an English naturalist, geologist, and biologist,\n widely known for his contributions to evolutionary biology. His proposition that\n all species of life have descended from a common ancestor is now generally\n accepted and considered a fundamental scientific concept. In a joint\n publication with Alfred Russel Wallace, he introduced his scientific theory that\n this branching pattern of evolution resulted from a process he called natural\n selection, in which the struggle for existence has a similar effect to the\n artificial selection involved in selective breeding. Darwin has been\n described as one of the most influential figures in human history and was\n honoured by burial in Westminster Abbey.\n'))]
Storing into Memgraph
Once you have the data ready in a format of GraphDocument, that is, nodes and relationships, you can use add_graph_documents method to import it into Memgraph. That method transforms the list of graph_documents into appropriate Cypher queries that need to be executed in Memgraph. Once that's done, a knowledge graph is stored in Memgraph.
# Empty the database
graph.query("STORAGE MODE IN_MEMORY_ANALYTICAL")
graph.query("DROP GRAPH")
graph.query("STORAGE MODE IN_MEMORY_TRANSACTIONAL")
# Create KG
graph.add_graph_documents(graph_documents)
Here is how the graph looks like in Memgraph Lab (check on localhost:3000):
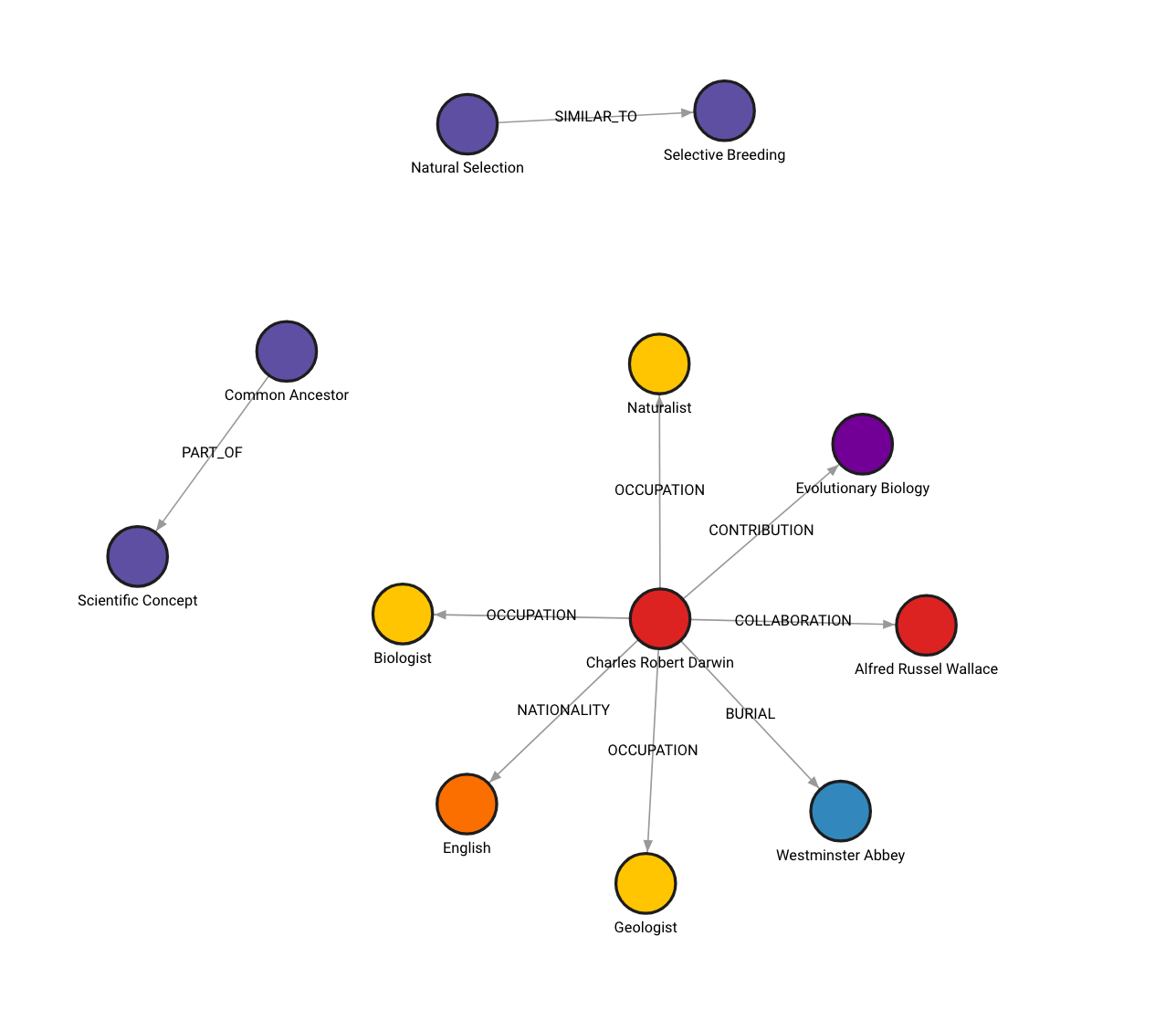
In case you tried this out and got a different graph, that is expected behavior. The graph construction process is non-deterministic, since LLM which is used to generate nodes and relationships from unstructured data in non-deterministic.
Additional options
Additionally, you have the flexibility to define specific types of nodes and relationships for extraction according to your requirements.
llm_transformer_filtered = LLMGraphTransformer(
llm=llm,
allowed_nodes=["Person", "Nationality", "Concept"],
allowed_relationships=["NATIONALITY", "INVOLVED_IN", "COLLABORATES_WITH"],
)
graph_documents_filtered = llm_transformer_filtered.convert_to_graph_documents(documents)
print(f"Nodes:{graph_documents_filtered[0].nodes}")
print(f"Relationships:{graph_documents_filtered[0].relationships}")
Nodes:[Node(id='Charles Robert Darwin', type='Person', properties={}), Node(id='English', type='Nationality', properties={}), Node(id='Alfred Russel Wallace', type='Person', properties={}), Node(id='Evolutionary Biology', type='Concept', properties={}), Node(id='Natural Selection', type='Concept', properties={}), Node(id='Westminster Abbey', type='Concept', properties={})]
Relationships:[Relationship(source=Node(id='Charles Robert Darwin', type='Person', properties={}), target=Node(id='English', type='Nationality', properties={}), type='NATIONALITY', properties={}), Relationship(source=Node(id='Charles Robert Darwin', type='Person', properties={}), target=Node(id='Evolutionary Biology', type='Concept', properties={}), type='INVOLVED_IN', properties={}), Relationship(source=Node(id='Charles Robert Darwin', type='Person', properties={}), target=Node(id='Alfred Russel Wallace', type='Person', properties={}), type='COLLABORATES_WITH', properties={}), Relationship(source=Node(id='Charles Robert Darwin', type='Person', properties={}), target=Node(id='Natural Selection', type='Concept', properties={}), type='INVOLVED_IN', properties={})]
Here's how the graph would like in such case:
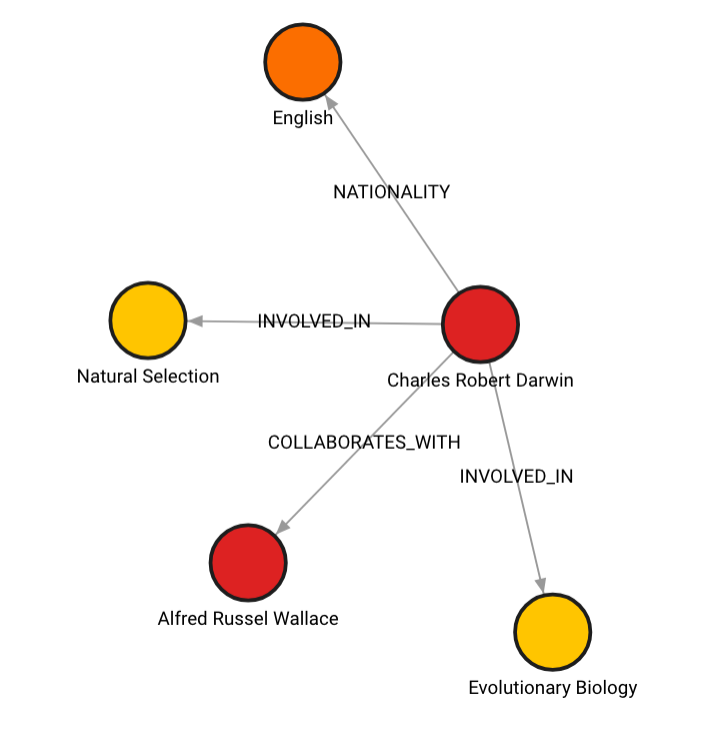
Your graph can also have __Entity__ labels on all nodes which will be indexed for faster retrieval.
# Drop graph
graph.query("STORAGE MODE IN_MEMORY_ANALYTICAL")
graph.query("DROP GRAPH")
graph.query("STORAGE MODE IN_MEMORY_TRANSACTIONAL")
# Store to Memgraph with Entity label
graph.add_graph_documents(graph_documents, baseEntityLabel=True)
Here's how the graph would look like:
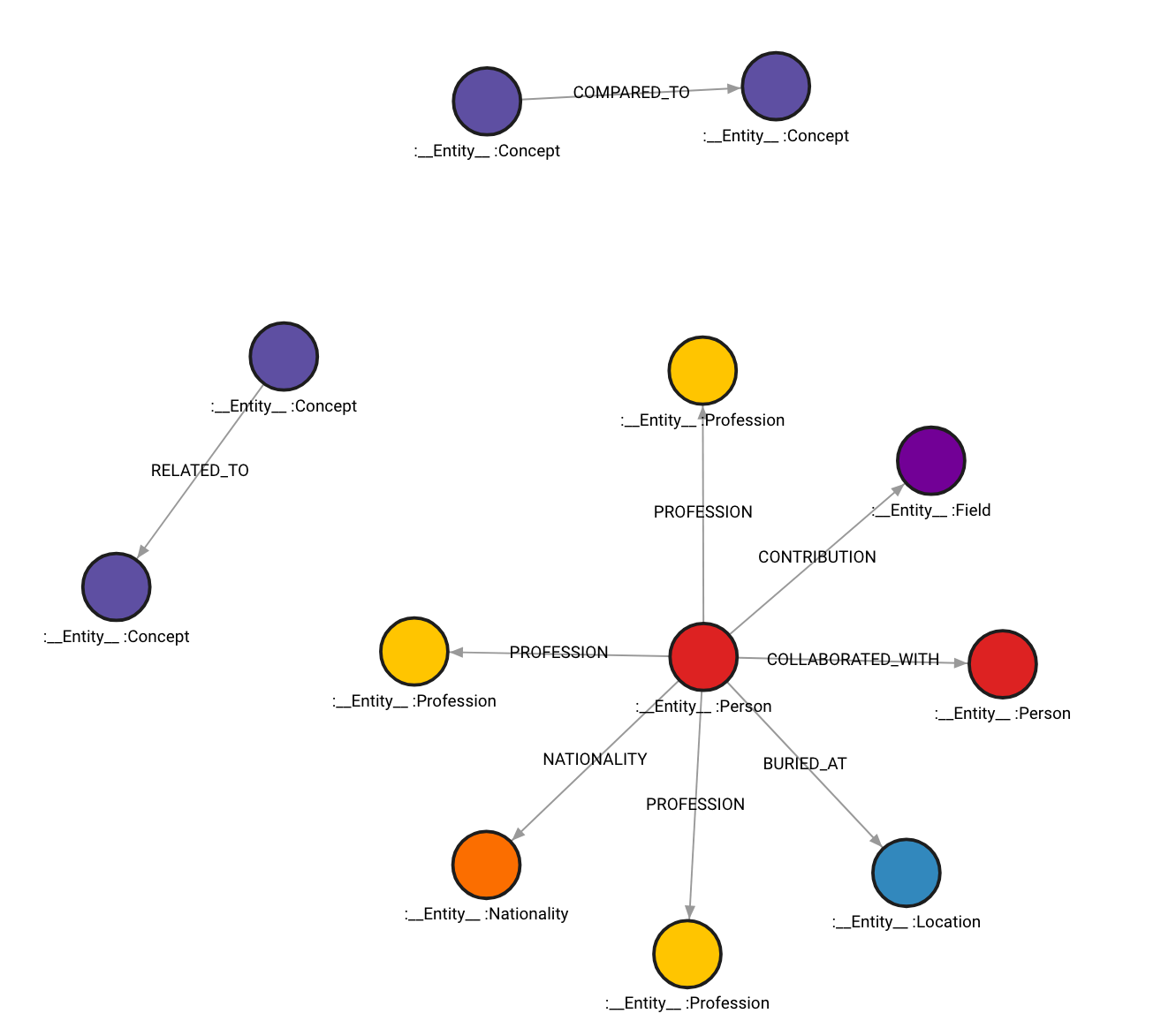
There is also an option to include the source of the information that's obtained in the graph. To do that, set include_source to True and then the source document is stored and it is linked to the nodes in the graph using the MENTIONS relationship.
# Drop graph
graph.query("STORAGE MODE IN_MEMORY_ANALYTICAL")
graph.query("DROP GRAPH")
graph.query("STORAGE MODE IN_MEMORY_TRANSACTIONAL")
# Store to Memgraph with source included
graph.add_graph_documents(graph_documents, include_source=True)
The constructed graph would look like this:
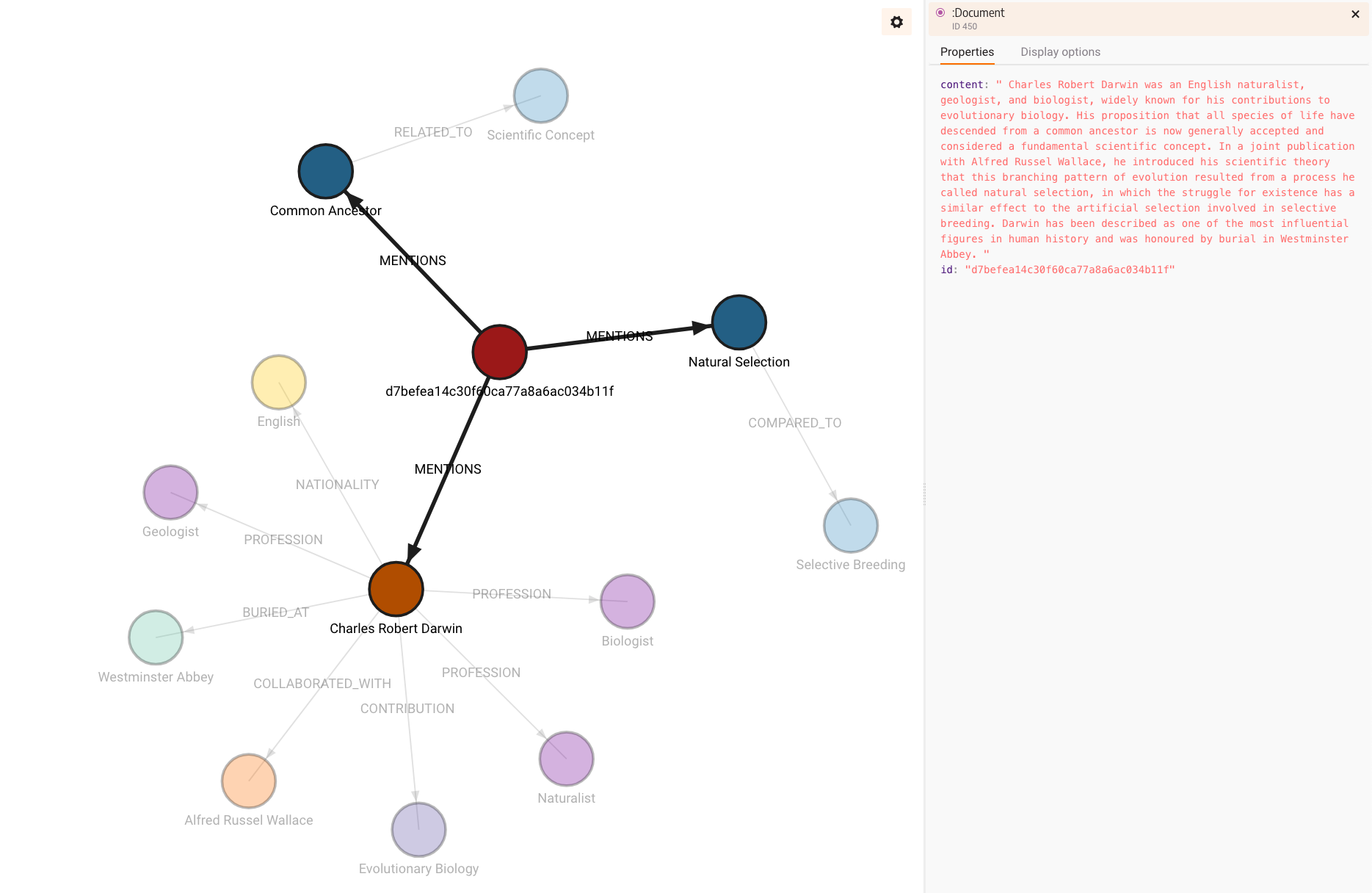
Notice how the content of the source is stored and id property is generated since the document didn't have any id.
You can combine having both __Entity__ label and document source. Still, be aware that both take up memory, especially source included due to long strings for content.